

What is Cloud Storage?
In this series, Rick Whittington will explore the benefits and potential risks of the Cloud for organizations. Rick will incorporate knowledge he’s gained as a reformed Network Engineer with multiple disciplines in Network, Security, Global Networks, Datacenter, Campus Networks, and Cloud Networks. He’ll also incorporate his years of experience in improving enterprise infrastructure, processes, and teams. Rick has brought his cloud experience to organizations such as Capital One, Charles Schwab and his current position as a Sr. Security Engineer for a large data analytics company.


Depending on the Google search, cloud storage can bring up multiple definitions for this seemingly basic term. Further complicating matters is if the service is an Infrastructure as a Service (IaaS), Platform as a Service (PaaS), or Software as a Service (SaaS) solution. Let’s define Cloud storage as “A server to store or retrieve remote files.”, the differentiator being the level of management of the remote server. Services like AWS S3, Azure Blob, and Dropbox are great examples of blurring the lines of ‘…as a Service’. Below is a breakdown of several solutions and how they relate to ‘as a Service’:
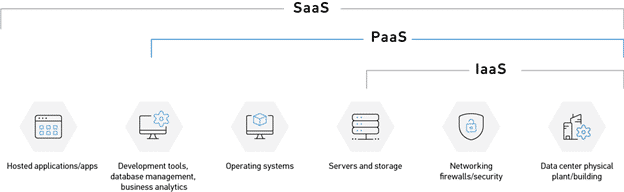
- IaaS
- Summary
- Bare metal solution requiring selection of components, such as RAM, CPU, Storage, and software, is installed and managed.
- Significant control in the configuration of overall deployment.
- AWS
- Elastic Block Storage (EBS)
- Elastic File System (EFS)
- Azure
- Disk Storage
- PaaS
- Summary
- The provider has already selected hardware and software.
- Focus on the development and management of applications over infrastructure control.
- AWS
- S3 Storage
- Redshift
- Rational Database Services (RDS)
- DynamoDB
- Azure
- Blob Storage
- NetApp Files
- CosmoDB
- SQL Database
- SaaS
- Summary
- Turn-Key solution with minimal administrative configuration
- AWS
- Amazon FSx for Windows
- S3 Storage
- Amazon Photos
- Azure
- File Storage
- Other Examples
- Dropbox
- Google Drive
With the many cloud storage options provided to organizations, it can be challenging to secure these solutions properly. The threats with on-premise storage and cloud storage can be different, but with the same data leakage and exfiltration outcomes, leading to a loss of confidence in the organization. For this article’s purpose, the focus will be on securing AWS S3 and Azure Blob Storage.
What is Object Storage?
Object storage differs from traditional file system storage and block storage in how the data is managed. Data managed in file systems are stored in a hierarchy, while block storage stores data as blocks within sectors and tracks. Object storage differs in managing the data as an object that contains the data, a globally unique identifier, and metadata, which can work with both structured and unstructured data. By providing globally unique identifiers, data replication and data distribution can be at an individual object level across many hardware systems. With the focus on data as objects, object storage provides an organization with the benefit of granular controls.
Common Security Issues
The risk associated with data storage varies in its deployment and use case. The common threat is data exfiltration or leakage; the risk of exposure within an on-premise data center is generally minimized within the organization network boundaries. Data stored in the Cloud has no defined network boundary leaving the inherent risk of being accessible globally. Most, if not all, security events involving cloud storage relate to permission or policy misconfiguration. While misconfiguration is the typical cause of data leakage, organizations should look at a comprehensive security approach to manage overall risk, such as:
- Encryption
- Management and Discovery
- Remediation
- Monitoring
Encryption
Many cloud providers offer server-side encryption as a recommended setting, with some providers using server-side encryption as a default configuration. Server-side encryption provides encryption of data when received by the destination, leaving the data, at-rest, encrypted. Although the data is encrypted at-rest, misconfigurations in permissions will leave information accessible. Using client-side encryption provides the most significant security benefit, decreasing the risk that a leakage event will yield usable data. Most organizational security focuses on external threat actors; however organizations should also consider malicious internal users. Using client-side encryption allows for the additional benefit of data privacy, both internally and externally, by encrypting the file’s actual contents.
Resources:
- AWS – Protecting data using encryption: https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingEncryption.html
- Azure – Storage encryption at rest: https://docs.microsoft.com/en-us/azure/storage/common/storage-service-encryption
Management and Discovery
Centralized management of assets in cloud environments is highly dependent on both the provider capabilities and the organizational deployment architecture. Many leverage multi-account architectures with providers such as AWS, treating each account as a unique environment. With individual accounts, both AWS and Azure provide compliance reporting to assist with managing and discovering misconfigurations. Unfortunately, in a multi-account architecture, centralized management of configurations such as permissions can become problematic. Both vendors and open-source developers have created solutions to ease the burden of managing and discovering misconfigurations across accounts.
The discovery of storage objects is critical to understanding the organizations cloud footprint. While the management of existing infrastructure can be accomplished in many ways, discovering new storage objects is vital to ensure that Organizational policies are applied to mitigate misconfigurations at creation. In addition to discovering new storage objects, organizations must review the object’s contents and use appropriate data classification to understand where critical data is stored. With data classification policies applied, files containing sensitive data can be further protected with additional permissions, encryption, or tokenization.
Resources:
- AWS: https://docs.aws.amazon.com/AmazonS3/latest/dev/s3-compliance.html
- Azure: https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-immutability-policies-manage?tabs=azure-portal
- Security Center: https://azure.microsoft.com/en-us/services/security-center/
Remediation
On-premise storage misconfiguration remediation traditionally exposes data internally, leaving the potential for risk to internal users. On-premise file-sharing solutions can be centrally managed, allowing for rapid remediation of permissions or misconfigurations. In contrast, and as previously stated, a misconfiguration within a cloud environment inherently reveals the data globally. With object storage, individual objects can leverage different permissions; the lack of centralized management and manually reconfiguring objects can be time-consuming. To lower the risk of data exposure at scale, organizations need to implement automated remediation. External threat actors leverage automation to discover misconfigured cloud storage; organizations choosing not to leverage automation to provide corrective action have a higher chance of exposure and loss of confidence from the public.
Resources:
- AWS – AWS Config: https://aws.amazon.com/blogs/mt/aws-config-auto-remediation-s3-compliance/
- Azure – Security Center: https://docs.microsoft.com/en-us/azure/security-center/security-center-remediate-recommendations
Monitoring
Monitoring for cloud storage can help determine who accessed the file object and audit any object permissions changes—in the event of data exposure, determining when the permissions were changed and list unauthorized access of the file. Configuration of access logs is completed at an object level, with configuration auditing at a service level. Monitoring, coupled with data classification, can aid in understanding the severity of the data leakage event. With the addition of configuration auditing, potential intent can be established.
Resources:
- AWS
- Logging and Monitoring in Amazon S3: https://docs.aws.amazon.com/AmazonS3/latest/dev/s3-incident-response.html
- Monitoring Amazon S3: https://docs.aws.amazon.com/AmazonS3/latest/dev/monitoring-overview.html
- Azure
Monitoring Blob Storage: https://docs.microsoft.com/en-us/azure/storage/blobs/monitor-blob-storage?tabs=azure-portal - Audit Logs: https://docs.microsoft.com/en-us/azure/security/fundamentals/log-audit
Best Practices for Policies and Permissions
With permissions and policies applied to cloud storage as the primary method of protecting against unauthorized access, it is critical to understand how to implement access control properly. Whether using AWS S3 or Azure Blob Storage, both utilize Identity and Access Management as a foundation. Identity and Access Management (IAM) can be applied to an entity (user or resource), giving the entity permission to access individual resources or complete services. In using access control to cloud storage, permissions may be granted to all objects or individual objects. A best practice in creating IAM Policies applied to resources is to specify explicit permissions and objects that can be accessed. In contrast, this may be difficult with user accounts as the user may be creating the initial storage object. However, specific permissions can be applied to user accounts to create limitations as well. The purpose of explicitly defining these permissions is to prevent a compromised resource from accessing non-authorized storage objects.
In conjunction with Identity and Access Management applied to users and resources, storage objects also have additional policies and permissions that can be set. In looking at the permission capability of objects, the capability is generally read and/or write, and in the case of AWS, can be further granted to a grantee (public, authenticated user, account). By adding a storage bucket policy, granular permissions can be defined, such as:
- Individual permissions (list, read, write, delete, tag)
- By specifying an IAM Role, an administrator can define individual permissions for access further. If an IAM Role allows full permissions to a storage bucket or object, the bucket’s restrictions will supersede role permissions.
- Grant Access to individual IAM Roles
- Like permissions, further specification of which roles are allowed access to a Storage Bucket lower the risk that an overly provisioned role may access sensitive data.
- Conditionals
- Conditionals allow additional criteria to be specified to access the storage objects. Examples of conditionals are source account, resource ID, or IP address.
While generic permissions may look easy to implement, the risk of misconfiguration and exposure is much greater. The best practice is to utilize bucket policies and define access granular as possible.
One last consideration for securing access to cloud storage is the use of private endpoints. By utilizing private storage endpoints, resources within the cloud network environment layer (compute resources) can access storage resources without being exposed to the public internet. In using a private connection, risks such as man-in-the-middle attacks can be reduced since all data communication stays within the local network environment.
Resources:
- AWS: https://docs.aws.amazon.com/AmazonS3/latest/dev/security-best-practices.html
- Azure: https://docs.microsoft.com/en-us/azure/storage/blobs/security-recommendations
Summary
When considering cloud storage, maximize overall risk with a layered security approach. Using a combination of encryption, auditing, management, automated remediation, and granular permissions will overall minimize data exposure. In our next installment of this blog series we’ll dig into cloud virtual machines and instances, so stay tuned!